
Getting started¶
Overview¶
pyRSKtools is RBR’s open source Python toolbox for reading, post-processing, visualizing, and exporting RBR logger data. Users may plot data as a time series or as depth profiles using tailored plotting utilities. Time-depth heat maps can be plotted easily to visualize transects or moored profiler data. A full suite of data post-processing functionality, such as methods to match sensor time constants and bin average, are available to enhance data quality. A “sample.rsk” file is available for testing purpose.
Basic usage¶
The first step is to connect to an RSK file by instantiating an RSK class object. The RSK.open() method
reads various metadata tables from the RSK file which contain information about the instrument channels, sampling configuration,
and profile events. It does not read the instrument data, please refer to the sections below to learn how to read data.
There are two approaches to instantiating and opening an RSK file, as shown below:
Manual approach:
from pyrsktools import RSK
# Instantiate an RSK class object, passing the path to an RSK file
rsk = RSK("/path/to/data.rsk")
# Open the RSK file. Metadata is read here
rsk.open()
# Read, process, view, or export data here
# ...
# Close the RSK file
rsk.close()
Context manager approach:
from pyrsktools import RSK
with RSK("/path/to/data.rsk") as rsk:
# Read, process, view, or export data here
The second approach uses Python with statement context manager provided by the RSK class to automatically
open the file (at the beginning of the context) and close it (at the end of the context). Except for the syntax,
the context manager approach is functionally the same as the manual approach. For the rest of this document, we
assume an RSK class has been instantiated and assigned to the variable rsk.
An instantiated RSK class may be printed at any time. Printing will provide useful information
about what attributes have been populated so far (including the number of elements in the case of a list/array type attributes).
An example of what printing may look like is provided below:
print(rsk)
RSK
Internal state attributes:
.filename is populated
.logs is populated with 1 elements
.version is populated
Informational attributes:
.appSettings is populated with 1 elements
.calibrations is populated with 9 elements
.channels is populated with 5 elements
.dbInfo is populated
.deployment is populated
.epoch is populated
.instrument is populated
.instrumentChannels is populated with 9 elements
.instrumentSensors is populated with 1 elements
.parameterKeys is populated with 25 elements
.parameters is populated with 1 elements
.power is populated with 1 elements
.ranging is populated with 5 elements
.regions is populated with 45 elements
.schedule is populated
.scheduleInfo is populated
Computational attributes:
.data is unpopulated
.processedData is unpopulated
To learn the differences between internal state, informational, and computational attributes, please refer to the API overview page.
Reading data from an RSK file¶
To read data from the instrument, use the RSK.readdata() method. This method will read the full dataset
by default. Because RSK files can store a large amount of data, it may be preferable to read a subset of the
data, specified using start and end times in NumPY datetime64 format. For example:
import numpy as np
t1 = np.datetime64("2022-05-03")
t2 = np.datetime64("2022-05-04")
rsk.readdata(t1, t2)
print(len(rsk.data))
# 77
print(rsk.channelNames)
# ('conductivity', 'temperature', 'pressure')
print(rsk.data["timestamp"])
# ['2020-10-02T18:00:00.000' ... '2020-10-02T18:10:00.000' ...]
print(rsk.data["temperature"])
# [15.49902344 15.76919556 12.08074951 ... 8.67211914 ...]
Note that the computational attribute RSK.data is a NumPY array object with column
labels (see NumPY dtype objects) specified by the channel metadata read by
RSK.open(). Refer to the API overview page for more information.
The channel names for each column in RSK.data are contained in
RSK.channelNames (excluding the “timestamp” column). Further, if
you would like to view additional information about channels (such as their units),
you may look into the RSK.channels list or, more conveniently, print them
by running:
rsk.printchannels()
# Model: RBRconcerto³
# Serial ID: 204571
# Sampling period: 10.0 seconds
# Channels: index name unit
# _____ ____________________________ ________
# 0 conductivity mS/cm
# 1 temperature °C
# 2 pressure dbar
To plot the data as a time series, use RSK.plotdata().
Working with profile regions¶
RSK.readdata() reads the instrument data into a single time series as opposed to a series of profile regions.
When Ruskin downloads data from a logger with a pressure channel, it will detect, timestamp, and record profile
upcast and downcast “events” automatically. Users may wish to interact with their data as a series of profiles instead of a
time series.
The RSK.getprofilesindices() method reads CTD data and returns a list of profile/cast indices.
In other words, each element in the returned list is a list itself which may be used to index into RSK.data
to get all the data points for that respective profile/cast. For example, to read the upcast and downcast of the first
3 profiles (profiles start at index 0) from the RSK file, run:
rsk.readdata()
profiles = rsk.getprofilesindices(range(0, 3), direction="both")
for profileIndices in profiles:
print(rsk.data[profileIndices])
After reading the profiles, they may be plotted with RSK.plotprofiles().
Note: If profiles have not been detected by the logger or Ruskin, or if the profile timestamps do not
correctly parse the data into profiles, the method RSK.computeprofiles() can be used.
The pressureThreshold argument, which determines the pressure reversal required to
trigger a new profile, and the conductivityThreshold argument, which determines if the logger
is out of the water, can be adjusted to improve profile detection when the profiles were very shallow, or
if the water was very fresh.
pyRSKtools includes a convenient plotting option to overlay the pressure data with information about the
profile events. See RSK.plotdata() for more details.
Deriving new channels from measured channels¶
In this particular example, practical salinity can be derived from conductivity, temperature, and
pressure because the file comes from a CTD-type instrument. RSK.derivesalinity() is a wrapper for the
TEOS-10 GSW function gsw_SP_from_C, and adds a new channel called "salinity" as a column
in RSK.data. The official Python implementation of the TEOS-10 GSW toolbox is freely available
and can be found here.
Salinity is a function of sea pressure, and sea pressure must be derived from the measured total pressure before computing salinity. In the following example, the default value of atmospheric pressure at sea level, 10.1325 dbar, is used:
rsk.deriveseapressure()
rsk.derivesalinity()
A handful of other EOS-80 derived variables are supported, such as potential temperature and density. pyRSKtools also has wrapper methods for a few common TEOS-10 variables such as absolute salinity.
Plotting¶
pyRSKtools contains a number of convenient plotting utilities. If the data can be organized as profiles, then it
can be easily plotted with RSK.plotprofiles(). For example, to plot the upcasts of temperature, salinity,
and chlorophyll, run:
import matplotlib.pyplot as plt
fig, axes = rsk.plotprofiles(
channels=["temperature", "salinity", "chlorophyll"],
direction="up",
)
plt.show()
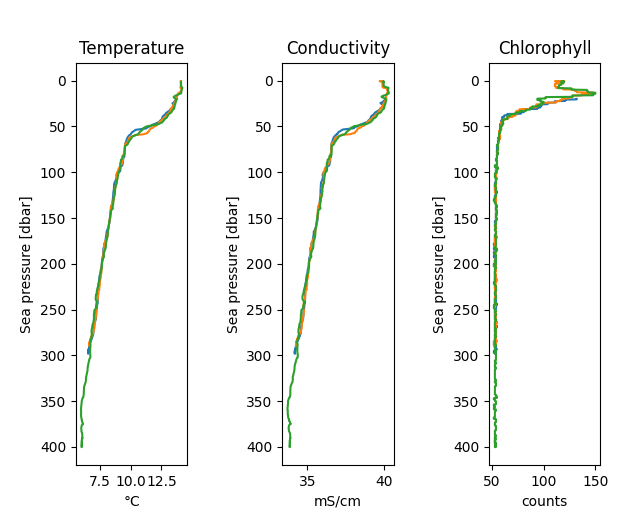
Customizing plots¶
The plotting methods return matplotlib handles to give access to the figure and a list of axes objects (one for each subplot). With such access, you may edit certain properties before showing your plots.
For example, to increase the line width of the first profile in all subplots (before calling plt.show()) of the above example, run:
for ax in axes:
plt.setp(ax.get_lines()[0], linewidth=6)
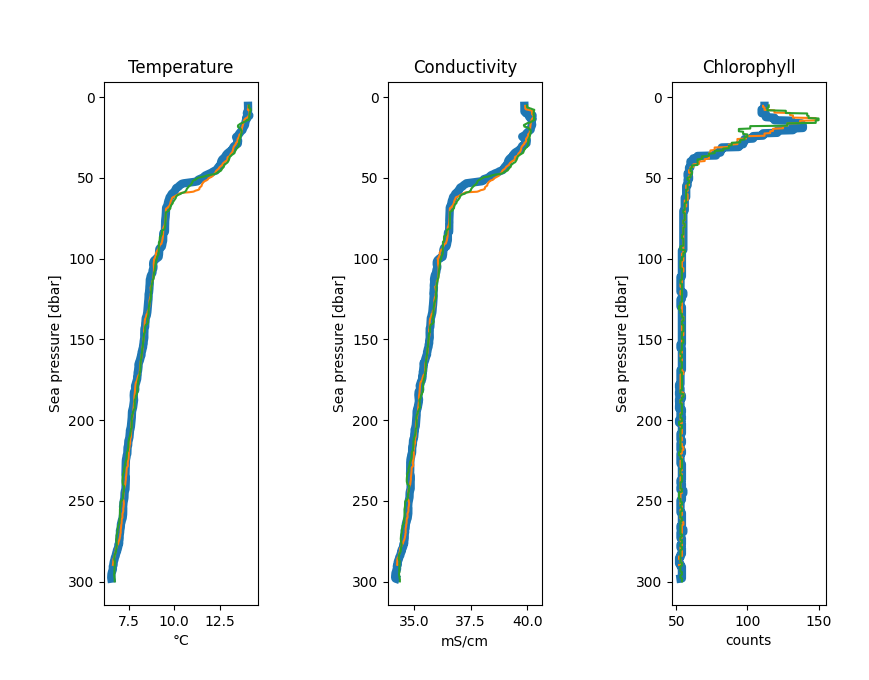
Other resources¶
In addition to the API documentation, we recommend reading the post-processing guide for an introduction on how to process RBR profiles with pyRSKtools. The post-processing suite contains, among other things, methods to smooth, align, de-spike, trim, and bin average the data. It also contains methods to export the data to CSV files.